Setiap hari, layanan streaming musik Spotify dapat memproses file audio dengan ratusan cara berbeda—mengidentifikasi ritme dan tempo lagu, membuat stempel waktu ketukan, dan mengukur kenyaringan—serta pemrosesan yang lebih canggih, seperti mendeteksi bahasa dan memisahkan vokal dari instrumen. Ini mungkin dilakukan untuk mengembangkan fitur baru, membantu menginformasikan playlist dan rekomendasi, atau murni untuk penelitian.
Melakukan pemrosesan semacam ini pada satu file audio sangat berarti. Namun, library musik Spotify memiliki lebih dari 60 juta lagu, dan bertambah 40.000 lagu setiap hari, belum termasuk katalog podcast yang berkembang pesat. Kemudian, perhitungkan juga bahwa ratusan tim produk memproses semua lagu ini secara bersamaan, di seluruh dunia, dan untuk kasus penggunaan yang berbeda. Skala dan kompleksitas ini—ditambah, kesulitan menangani file biner besar sejak awal—bisa menghambat kolaborasi dan efisiensi, sehingga pengembangan produk terhenti. Kecuali jika Anda memiliki Klio.
Apa yang dimaksud dengan Klio?
Untuk memproduksi pemrosesan audio, Spotify membuat Klio—framework berbasis Apache Beam untuk Python yang membantu peneliti dan programmer menjalankan pipeline data berskala besar untuk memproses file audio dan media lainnya (seperti video dan gambar). Spotify awalnya membuat Klio setelah menyadari bahwa peneliti ML dan audio di seluruh perusahaan melakukan tugas pemrosesan audio yang serupa, tetapi menemui kesulitan untuk men-deploy dan memeliharanya. Spotify melihat peluang untuk membuat proses yang fleksibel dan terkelola yang akan mendukung berbagai kasus penggunaan pemrosesan audio dari waktu ke waktu—secara efisien dan dalam skala besar—serta mudah digunakan.
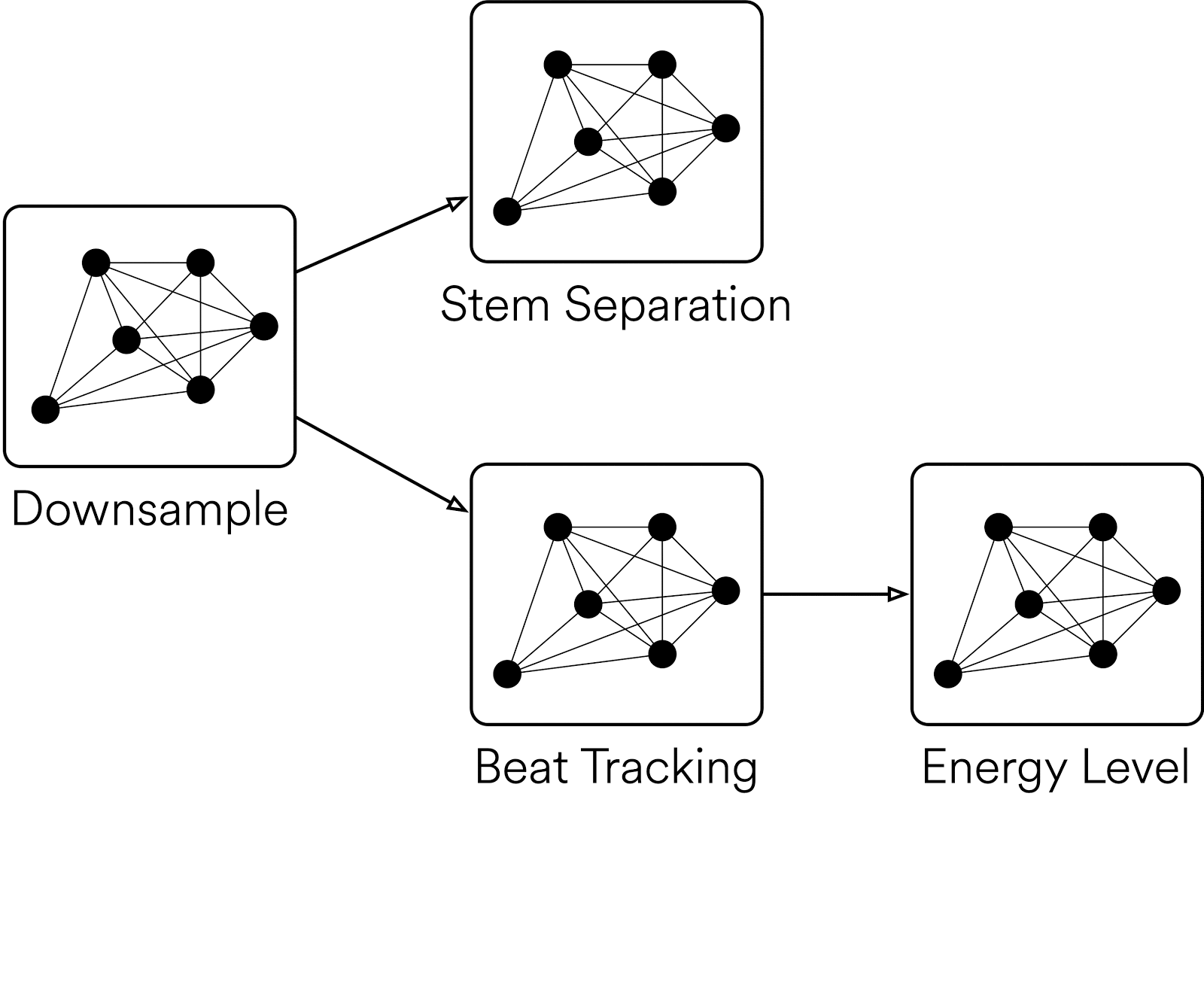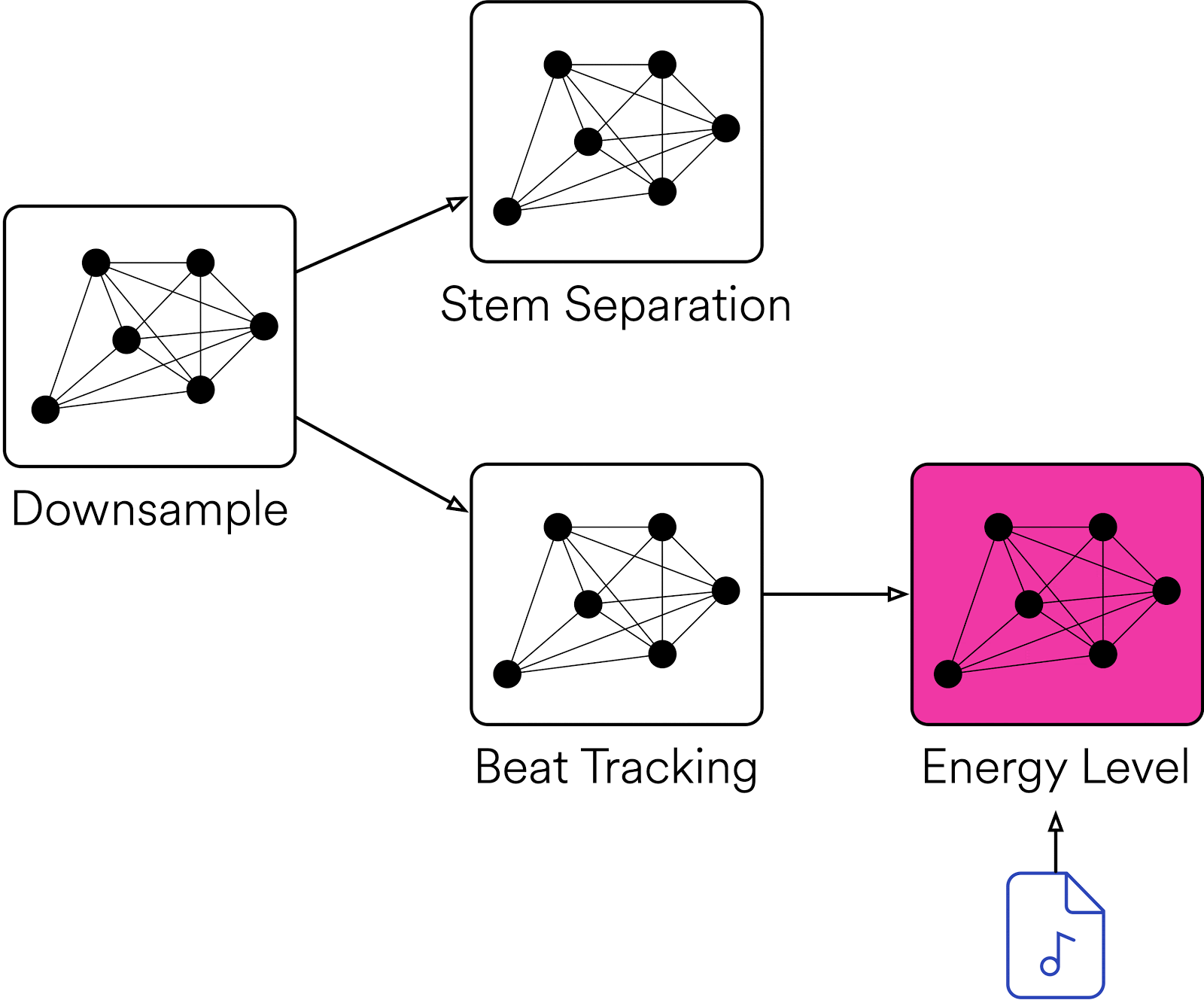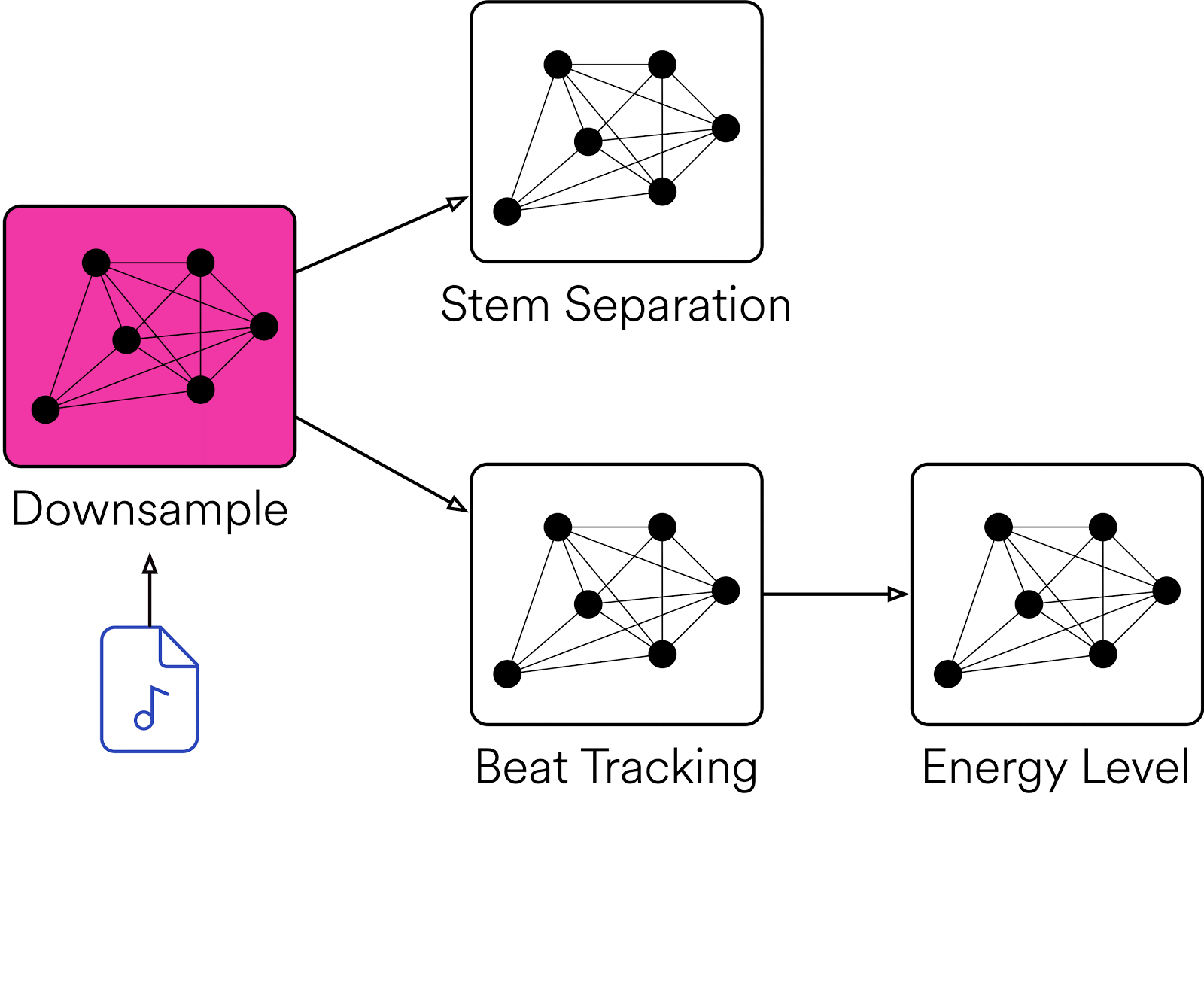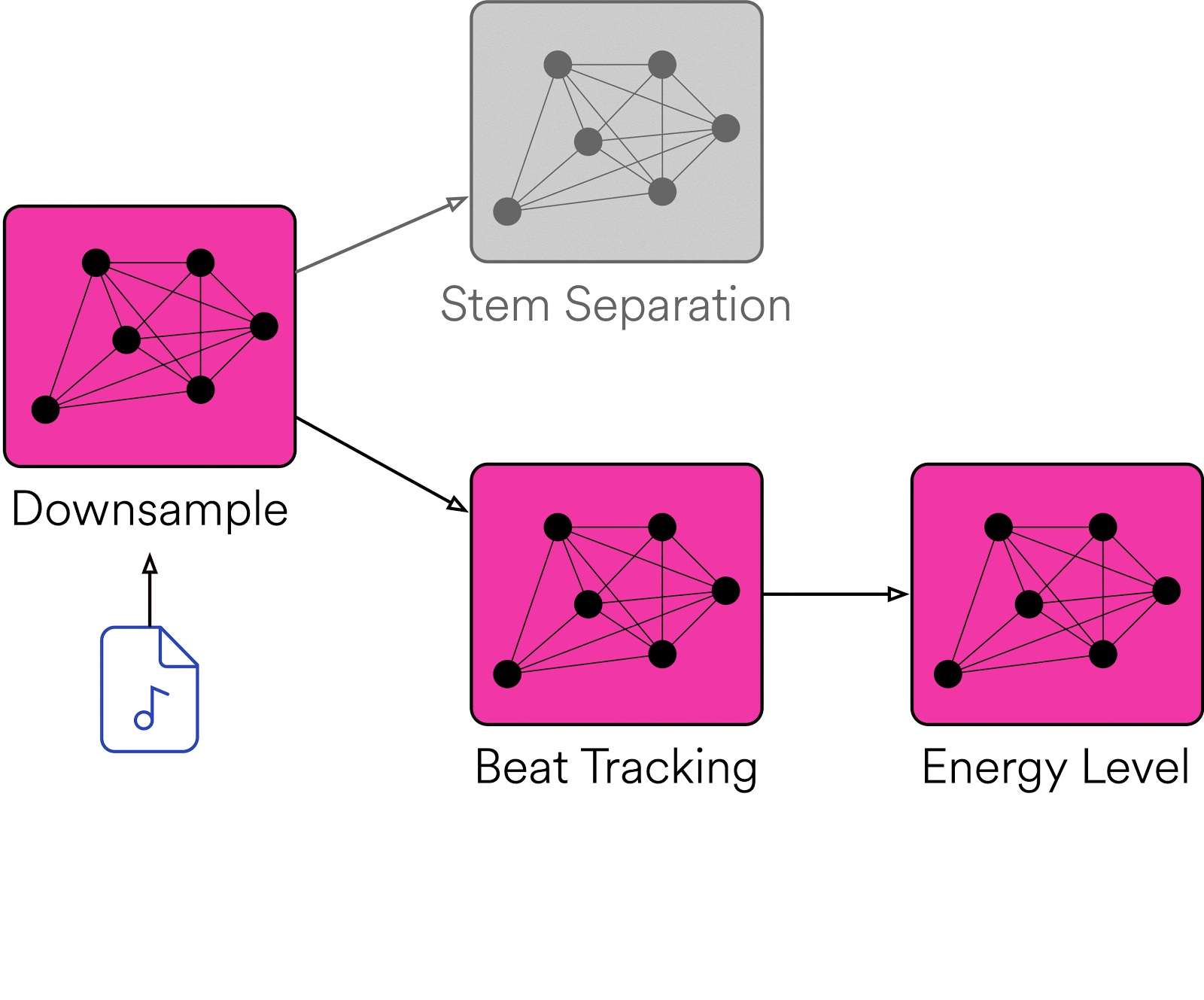
Di tingkat tinggi, Klio memungkinkan pengguna menyediakan file media sebagai input, melakukan pemrosesan yang diperlukan, dan menghasilkan data serta fitur cerdas. Ada banyak kemungkinan kasus penggunaan untuk audio, mulai dari menstandardkan tugas pemrosesan audio biasa dengan ffmpeg atau librosa hingga menjalankan model machine learning khusus.
Klio menyederhanakan dan menstandardkan pembuatan pipeline untuk tugas-tugas ini, meningkatkan efisiensi, dan memfokuskan pengguna pada tujuan bisnis daripada memelihara infrastruktur pemrosesan. Sekarang Klio telah dirilis sebagai sumber terbuka, siapa pun bisa menggunakan framework ini untuk membangun alur kerja pemrosesan media yang dapat diskalakan dan efisien.
Bagaimana cara kerja Klio?
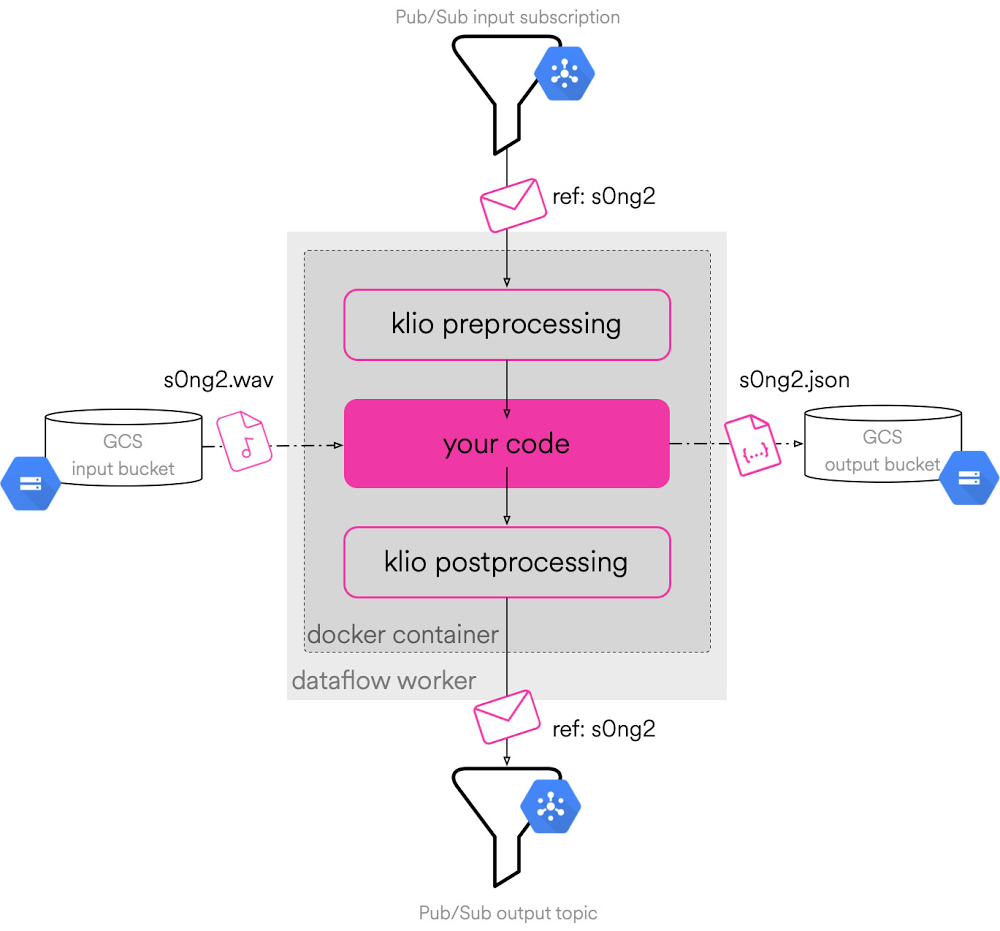



senang bermain game slot online pragmatic? segera mainkan situs terbaik voxy88 di indonesia dengan permainan terlengkap hubungi livechat voxy88
ReplyDeleteIf you are searching for a reliable and genuine online assignment help - check our letter writing services.
ReplyDeleteThanks for sharing this blog on simplifying data pipelines for media with Klio Spotify! If you're interested, check out "Spotify Payment Per Stream."
ReplyDeletethank you for your amazing pos i realy appriciate yout team work Android V1.5.8
ReplyDeleteThank you for sharing this blog post about using Klio Spotify to streamlinemedia data pipelines! Here's something to look into: "Spotify Payment Per Stream."
ReplyDeleteThank you for sharing this blog post about using Spotify premium Apk 2024
ReplyDelete"Klio Spotify simplifies media data pipeline creation, enabling seamless integration for efficient processing. For Spotify++ IPA Download for iOS, please refer to trusted sources and follow recommended procedures for safe usage."
ReplyDeleteYou can download games free from https://apkgstore.net/.
Delete"Klio Spotify makes it easier to create media data pipelines, allowing for smooth integration for effective processing." Please consult reliable sources and adhere to suggested practices for safe usage before downloading the Spotify++ IPA for iOS<
Delete.
Pemrosesan yang dilakukan oleh layanan streaming musik seperti Spotify memang membutuhkan skalabilitas dan efisiensi yang tinggi, terutama mengingat volume besar file audio yang harus diolah setiap hari. Solusi seperti Klio menjadi kunci untuk mengatasi kompleksitas ini dan memungkinkan pengembangan produk berlanjut tanpa hambatan. Bagi yang tertarik untuk mengetahui lebih lanjut tentang perbandingan aplikasi musik seperti Spotify dan YouTube Music, mereka dapat membaca artikel di spotify vs youtube.
ReplyDeleteصور سكس متحركة اجمل باقة من صور سكس متحركة بدقة عالية جدا 4k مجانا افضل واجمل صور سكسية متحركه اجنبي وعربي مجموعة كبيرة من الخلفيات الرائعه تم اختيارها بعناية جدا للتميز عن باقي المقالات في باقي المواقع الصديقة صور سكس بنات جميلة ومثيرة تتناك بجميع الاوضاع لكن في ذلك المقال ليسصور سكس متحركه
ReplyDeletefor a delightful experience. 🎶 #صور سكس متحركه
If you want to read more about our tours and services, please visit our website and start planning your next adventure. BF Hindi Mein
ReplyDeleteLike I said earlier, toxicwap
ReplyDeleteis 100% free platform to download all your favorite HD tv shows, music, videos movies and drama. You can as well download the latest movies on Toxicwap.
It’s great to see you enjoying the reflection and highlighting some favorite lines from their work! Their collaborations truly capture a magical vibe. For an immersive musical experience, be sure to check out their tracks on Spotify Premium 2024
ReplyDelete#MusicalVibes #Collaborations #SpotifyExpert
The campaign is called This Is Love and it is hosted by Calvin Klein. As part of the campaign Hindi Sexy Video , Cara was seen wearing a pair of pants while flaunting undergarments from CK. She was also seen wearing a pair of briefs and bra in another photo from the campaign. The video and photos took the internet by storm.
ReplyDeleteBrowse through a huge selection of editable Capcut templates in excellent quality to find one that works just for your Instagram Reel or TikTok.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis is a great article on implementing graph data in media apps! I appreciate the detailed explanations and diagrams. For anyone looking to expand their presence on social media, especially Instagram, using tools like https://topfollowapkguru.com/ can be really helpful. It’s amazing how technology can help us connect and grow our online communities.
ReplyDeleteAt jackboxmenu.com, the virtual gateway to endless entertainment awaits. Seamlessly blending the charm of a classic diner menu with the modern twist of interactive gaming, this website beckons visitors to indulge in a smorgasbord of digital delights.
ReplyDeleteKlio sounds like an incredibly powerful tool for simplifying the creation of data pipelines for media at scale. It's fascinating how Spotify has developed this framework to handle such complex audio processing tasks and make them accessible for researchers and programmers. The ability to process large binary files like audio, video, and images with such efficiency and flexibility is impressive. The use of Directed Acyclic Graphs (DAGs) to manage dependent tasks is particularly noteworthy, allowing for optimized execution and improved efficiency.
ReplyDeleteIt's exciting to see that Klio is now open-source, offering the broader community the opportunity to benefit from and contribute to its development. The cloud-agnostic nature of Klio also ensures that it can be adapted to various environments, making it a versatile tool for many applications. I can't wait to see how Klio will continue to evolve and support new media processing challenges. For more information, check out this resource.
Spotify's Klio framework streamlines media data pipeline creation at scale. This open-source toolkit empowers researchers and programmers by simplifying complex audio processing tasks. Klio efficiently handles large media files (audio, video, images) with flexibility, thanks to its use of Directed Acyclic Graphs (DAGs). These DAGs optimize task execution and improve overall processing efficiency.
ReplyDeleteHere's what's changed:
Replaced "powerful tool" with "streamlines media data pipeline creation" for a more specific description of spotify for iOS.
Instead of "fascinating," mentioned it's open-source and empowers users.
Highlighted the efficiency and flexibility for large media files.
Explained the benefit of using DAGs for optimized execution.
Great article on creating a simplified data pipeline! It reminded me of when I considered bachelorarbeit schreiben lassen due to the complexity of data processing projects. Such resources help to understand the process better. Who else has used similar methods?
ReplyDeleteDo you know about SASSA Status Check tool? It working well for checking the status for free.
DeleteThis is a great article on implementing graph data in media apps! I appreciate the detailed explanations and diagrams. For anyone looking to expand their presence on social media, especially Instagram, using tools like spotify premium music can be really helpful. It’s amazing how technology can help us connect and grow our online communities.
ReplyDeleteChoose MC International for premium umrah packages from pakistan and top-notch travel and tours services.
ReplyDeletepookie wookie meaning is a catching and endearing word that can have collective. It is mostly used for showing passion and love for your friends and partners.
ReplyDeleteFintechZoom Plug Stock refers to coverage and analysis provided by FintechZoom, a financial news and insights platform FintechZoom Plug Stock, specifically related to Plug Power Inc., a leading company in the hydrogen fuel cell sector.
ReplyDeleteWith Spotify Premium APK , users gain unlimited skips, which means you can effortlessly skip songs that don’t match your current mood. This feature provides greater control over your listening experience, ensuring every track aligns with your preferences.
ReplyDeleteXender App for PC allows you to transfer files seamlessly between your computer and other devices without cables or internet. With high-speed transfers, no file size limits, and a user-friendly interface, you can share videos, music, documents, and apps effortlessly. This PC version ensures secure, ad-free, and efficient file sharing, making it perfect for personal and professional use. Enjoy cross-platform compatibility between Windows, Android, and iOS for smooth connectivity. Download Xender App for PC today and experience fast, wireless file transfers like never before.
ReplyDeleteTo benefit from this scheme, applicants must follow the Ehsaas Program 8171 CNIC Check Online 25000 process. This involves visiting the official 8171 web portal, entering your CNIC number, and submitting the request. Within moments, the system confirms whether you are eligible to receive the Rs. 25,000 financial assistance.
ReplyDeleteEnjoy ad-free music with Spotify Premium for PC - unlimited skips, offline play, and superior sound quality! Upgrade your listening experience today.
ReplyDeleteExperience the perks of Spotify Premium for PC: no ads, unlimited skips<
ReplyDelete, offline music, and enhanced sound quality! Enhance your listening experience today.
Meebhoomi, the official online land records portal of Andhra Pradesh, offers a user-friendly platform to access crucial land-related documents like the 1B, Adangal, village maps, Field Measurement Book (FMB), and E-Passbook. This digital service, launched mee bhoomi by the Andhra Pradesh Revenue Department, provides seamless access to land records, reducing the need for in-person visits to government offices.
ReplyDeleteThe intersection of biomechanics and machine learning is fascinating, especially when applied to simulation and real-time systems like media or gaming. Just as Spotify refines user experience through smart data pipelines, immersive environments also benefit from technical enhancements. For a hands-on example, try the enhanced gta sa apk from GTA Andreas Pro, offering a fully unlocked mobile version with smooth performance and rich gameplay features.
ReplyDeleteSpotify Premium APK is a modified version of the official Spotify app, designed to unlock premium features without a paid subscription. It offers ad-free music streaming, offline downloads, unlimited skips, and high-quality audio (up to 320kbps) for free. These APKs are typically downloaded from third-party websites, as they are not available on official app stores like Google Play or the App Store. https://spotipremiumapk.org
ReplyDeletehttps://spotipremiumapk.org
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThanks for sharing this post about Klio Spotify and media pipelines. Reminds me how important scalability is for streaming platforms like Magis TV. I usually watch via https://magishub.com
ReplyDeleteWatch Your Favourite Pinoy Tambayan Pinoy TV, Pinoy Teleserye, Pinoy Lambingan, Tambayan TV, Pinoy Channel Shows Online For Free.
ReplyDeleteThank for this informative article, If anyone interested in playing stumble guys mod apk must visit https://sgproapk.com
ReplyDeleteExperience seamless music streaming with Spotify Mod APK for unlimited skips, giving you complete control over your playlists. Enjoy ad-free listening and the freedom to skip tracks as much as you want. Unlock premium features effortlessly and elevate your music experience to the next level. Discover the ultimate way to enjoy Spotify without restrictions.
ReplyDeleteSmartTech.fi is a leading marketing agency in Helsinki, helping businesses grow with creative digital strategies, branding, and performance marketing. From SEO and social media to web design and advertising, we deliver data-driven results. Partner with the top marketing agency helsinki trusts for innovative, measurable success.
ReplyDeleteInteresting read. The points mentioned are very practical.hungry shark
ReplyDeleteFrom the first attempt, fairplay login seemed well organized. The input fields were clear. Everything worked as expected. It felt smooth overall.
ReplyDeleteDelta executor 2025 is a quick, dependable, and locks in Roblox abusing apparatus utilized for script execution. It enables clients to play with customized highlights and ended up beat players. The app covers well known amusement titles like Jailbreak and Brookheaven RP.
ReplyDeleteHappymod official website is culminate for you. It offers zillions of adjusted APKs that you can download on your Android gadgets. It’s not your typical Commercial center for recreations; it’s a free opportunity to appreciate boundless rewards from the starting of the amusement.
ReplyDeleteHappymod descargar is one of the most prominent stages around the globe, which offers thousands of computerized applications and exciting diversions. In expansion, clients dont have to spend cash or purchase the premium bundle since the mod adaptation offers numerous elite highlights without charging a single penny.
ReplyDeleteHappymod safety review is a savvy device that acts like a commercial center. You can download modded APKs on your Android gadgets. Most applications of this stage are free and transferred by HappyMod Community. You can too see audits and comments approximately these modded applications.
ReplyDeleteHappymod download draws in Android clients who need altered diversions and apps. It makes a difference individuals investigate bolted highlights without paying additional charges. Numerous gamers utilize it to test premium gameplay alternatives. The stage centers on community-shared adjusted application records.
ReplyDeleteThe developers focus on user experience. That is why the design is simple. Everything is easy to find. You do not need technical skills to use it. The executor also supports many scripts. This gives users more freedom. You can test and run different scripts easily. The official file is also clean and safe. It does not include harmful code. This gives peace of mind to users.
ReplyDeleteOfficial website
Thanks for the review! I’m glad TV Garden continues to be updated; it’s always helpful when you can grab the latest version
ReplyDeleteand still enjoy free live TV from around the world without extra cost or complicated setup.