Panduan praktis untuk menerapkan machine learning dalam dunia kesehatan
Kesehatan adalah industri yang memunculkan harapan tertinggi mengenai manfaat potensial dari Kecerdasan Buatan (AI). Dokter dan peneliti medis tidak akan menjadi programmer atau data scientist dalam semalam, mereka juga tidak akan digantikan olehnya, tetapi mereka membutuhkan pemahaman tentang apa itu sebenarnya AI dan bagaimana cara kerjanya. Demikian juga, data scientist perlu bekerja sama erat dengan dokter untuk berfokus pada pertanyaan medis yang relevan dan memahami pasien di balik data tersebut.notebook Colab ) yang berfokus dalam memahami mekanisme yang mendasari model machine learning terapan.Pertanyaan medis dibingkai sebagai masalah machine learning terarah
Ambil data dan bersihkan
Analisis data lalu ekstrak fitur yang relevan dengan masalah tersebut
Rancang strategi validasi
Latih algoritme dengan data tersebut, analisis error, dan interpretasikan hasilnya
Ulangi terus sampai kinerja terbaik algoritme didapatkan.
Catatan: Dalam pekerjaan ini, kami menggunakan Python, salah satu bahasa pemrograman paling populer dalam machine learning. Untuk pengguna baru, kami mengundang Anda untuk mengeksekusi baris kode pertama di notebook Colab untuk mengetahui cara kerjanya.
Pengumpulan Data
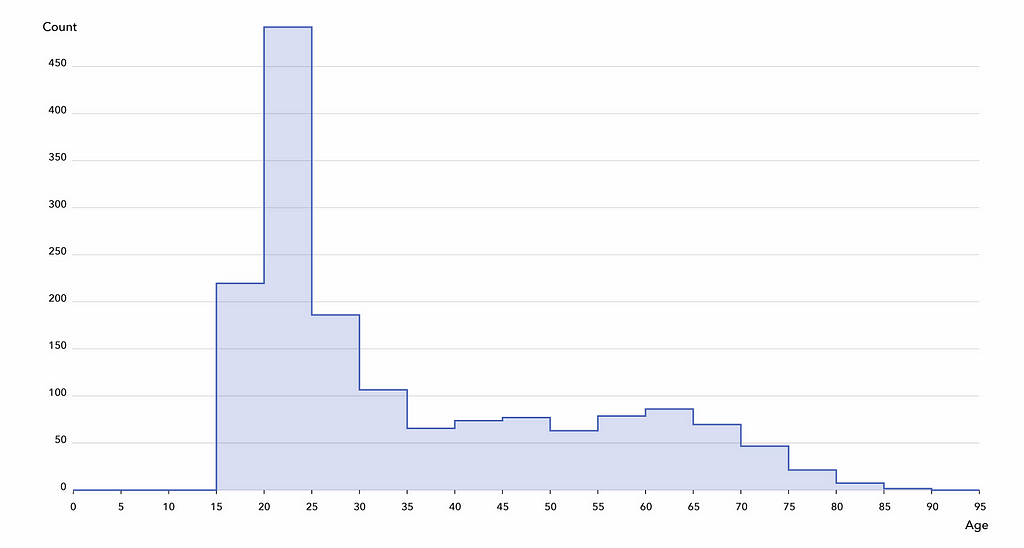
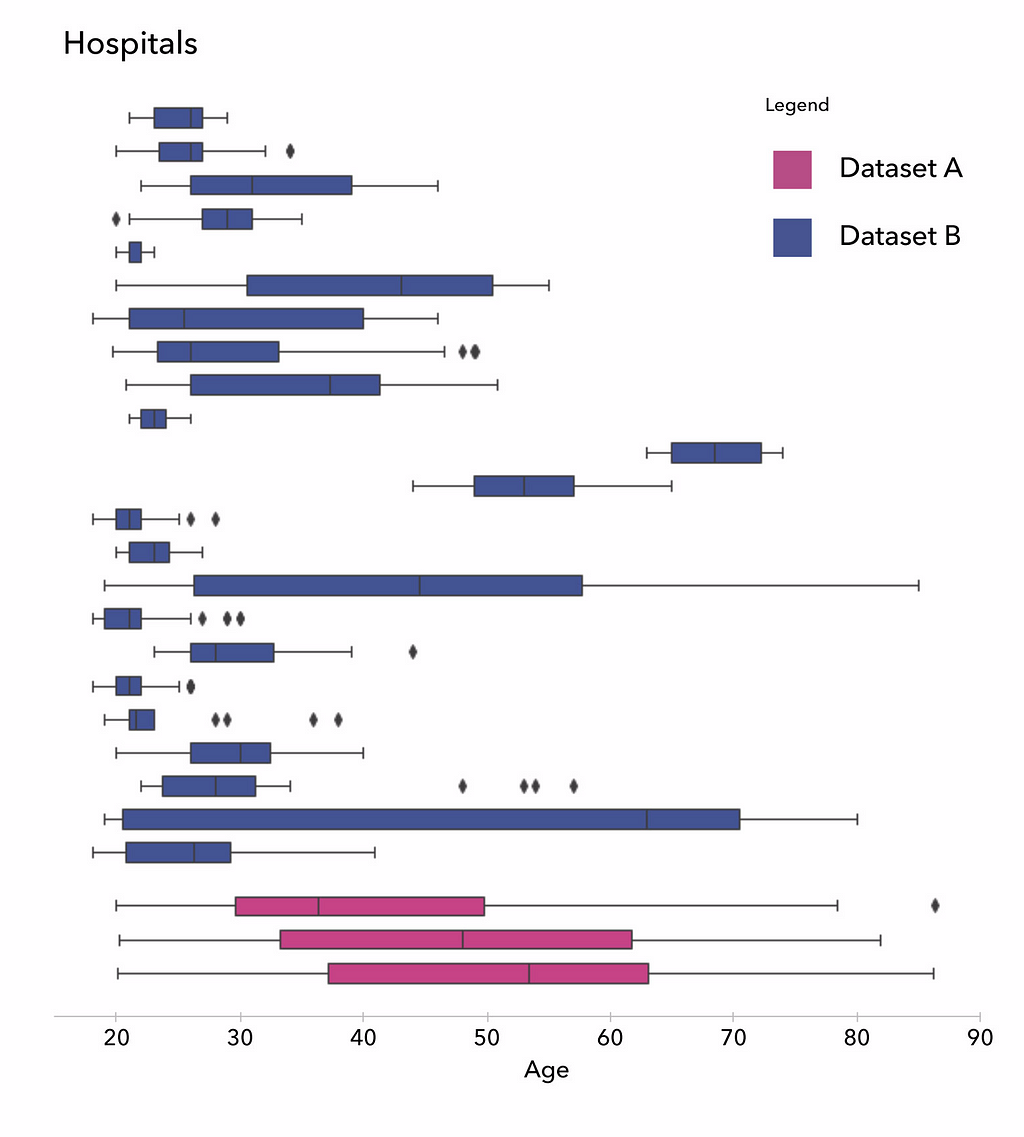
Untuk project ini, kami menggunakan dua set data MRI otak yang tersedia untuk publik dan anonim dari subjek yang sehat. Pertama, Set Data A , yang dikumpulkan di tiga rumah sakit London yang berbeda dan berisi data dari hampir 600 subjek. Kedua, Set Data B , yang berisi data dari lebih dari 1.200 subjek dari 25 rumah sakit di AS, Cina, dan Jerman. Error semacam itu sangat umum untuk set data medis.notebook Colab . Kami mengamati demografi berikut dalam kelompok: 55% adalah perempuan, yang termuda berusia 18 tahun, yang tertua berusia 87 tahun, dan kuartil usia 22, 27, dan 48.Histogram distribusi usia di antara 1.597 subjek, yang menunjukkan bias terhadap subjek yang lebih muda.
Sebelum Memproses Data
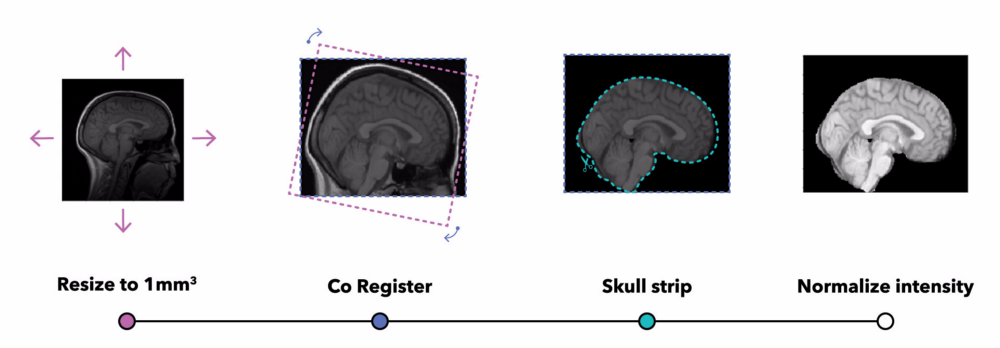
Saat membuka file yang berisi MRI, kami mengamati diferensiasi yang sangat tinggi antar masing-masing gambar: resolusi, nilai voxel, kolom tampilan, orientasi, dll. Oleh karena itu, diperlukan beberapa metode normalisasi agar kita bisa membandingkannya.ANTs untuk mendaftarkan semua gambar ke atlas (MNI152 ) dan melakukan skull stripping, kemudian menormalkan nilai intensitas voxel dengan menerapkan koreksi kolom bias N4 dan teknik yang populer, normalisasi white stripe . MRI bukanlah gambar kuantitatif, jadi yang perlu diperhatikan adalah perbedaan kontras.Pipeline prapemrosesan MRI.
Apa yang dokter ketahui tentang penuaan otak?
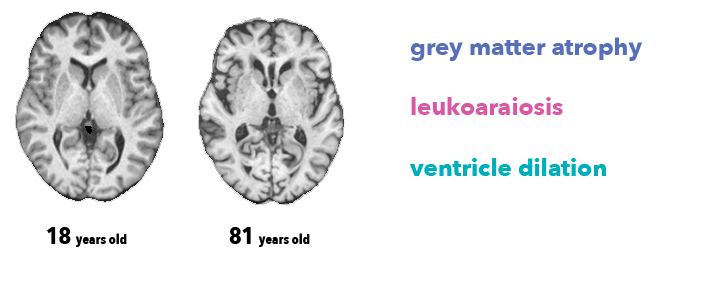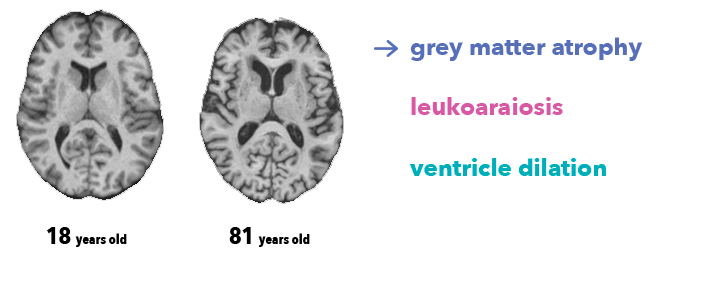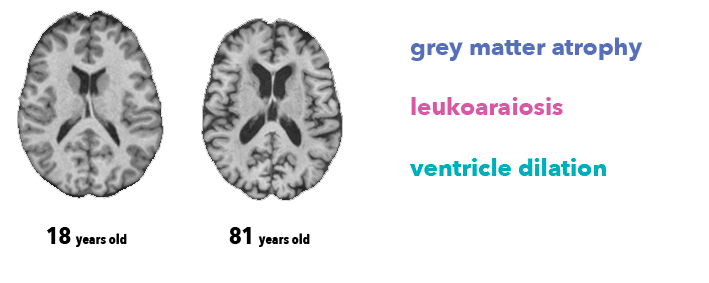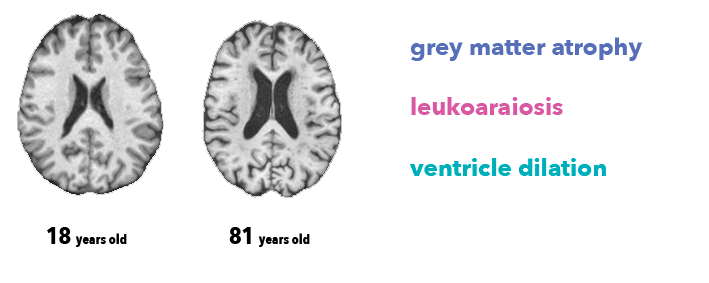
Tidaklah mungkin bagi dokter untuk menentukan usia subjek secara tepat hanya dari gambar otak. Namun, ahli radiologi tahu setidaknya ada tiga fitur anatomi yang terkait dengan penuaan otak, terlihat pada urutan MRI T1 yang kami gunakan dalam pekerjaan ini:
Atrofi, penurunan ketebalan materi abu-abu (karena hilangnya neuron)
Leukoaraiosis, yang muncul sebagai hipointensitas materi putih (karena penuaan pembuluh darah)
Dilatasi ventrikel, sebagai konsekuensi atrofi dan penumpukan cairan serebrospinal di ventrikel otak.
Perbandingan usia otak secara fisiologis dengan fitur-fitur yang diperjelas James Cole , rekan peneliti di King’s College London, telah menulis serangkaian makalah yang bagus tentang topik ini (Cole et al., 2017 adalah yang paling mirip dengan pekerjaan kami). Sebuah studi yang jauh lebih besar (Kaufmann et al., 2018 ) pada sekitar 37.000 pasien saat ini sedang ditinjau, dan keduanya tercakup dengan baik dalam artikel Quanta ini.
Memulai dengan baseline
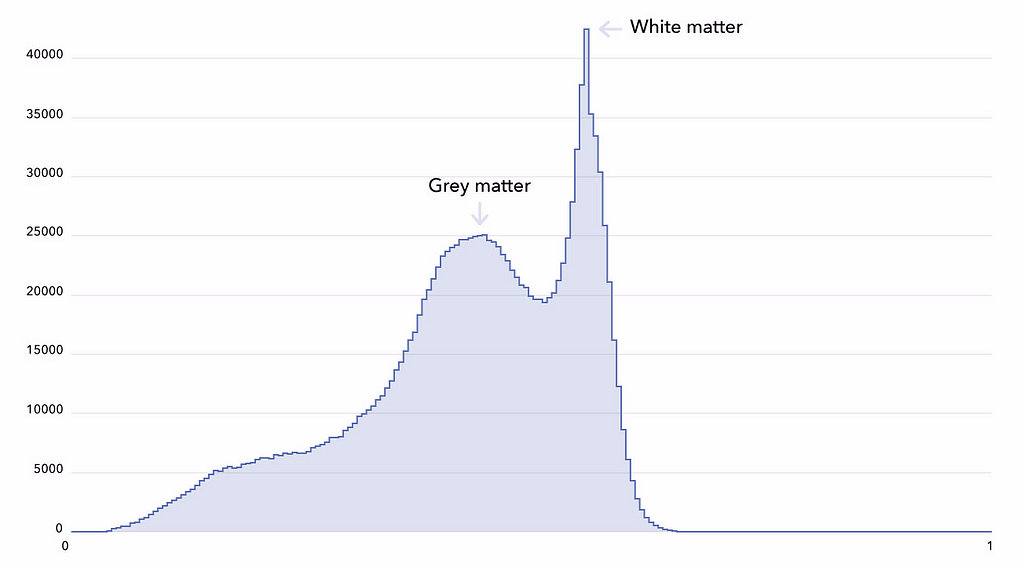
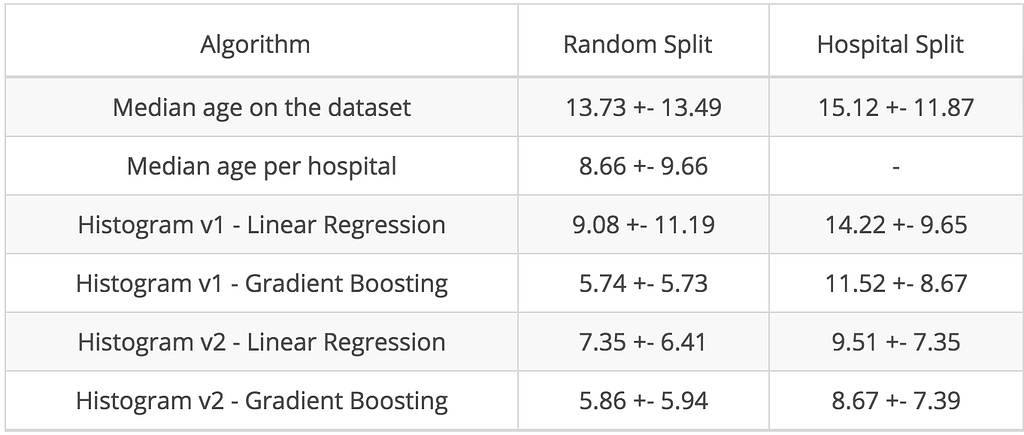
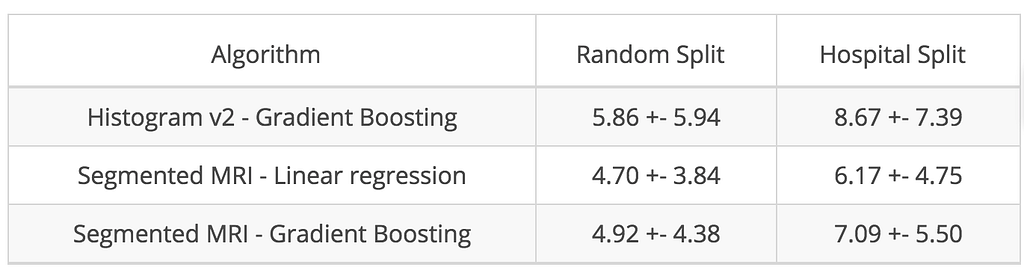
Untuk memahami kompleksitas masalah, kami mendefinisikan algoritme baseline sederhana. Kami memutuskan untuk tidak menggunakan seluruh 3D MRI, tetapi memakai refleksi yang lebih sederhana dari konten, histogram dari intensitas voxel mereka. Histogram khas T1-MRI ditunjukkan di bawah ini (bangun histogram Anda di notebook Colab ).Dua puncak tersebut merepresentasikan materi abu-abu dan materi putih. Seperti yang kita ketahui, penuaan berhubungan dengan atrofi materi abu-abu. Bisakah kita memprediksi usia otak dengan representasi yang belum sempurna ini? menggunakan 5-fold cross-validation, random split ). Gradient boosted trees memberikan hasil yang jauh lebih baik dan mengurangi error menjadi 5,71 tahun, yang jauh lebih dekat dengan kinerja termutakhir (4,16 tahun seperti yang dilaporkan dalam Cole et al. 2017 ). Termutakhir adalah titik henti yang menggoda, tetapi kami membuat kesalahan besar yang sayangnya, cukup umum.
Meninjau kembali cross validation
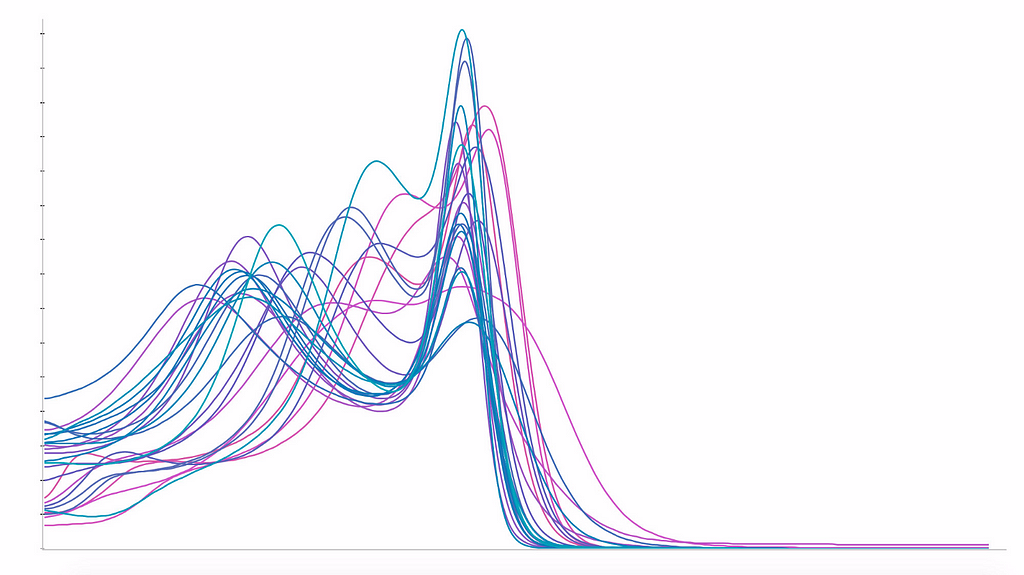
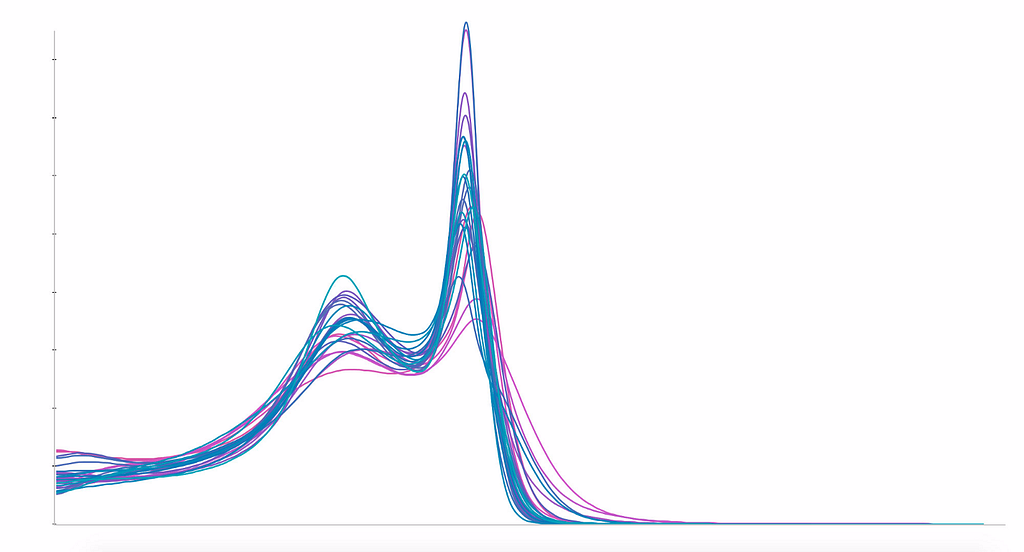
Kisaran intensitas voxel dalam MRI tidak memiliki arti biologis dan sangat bervariasi antara satu pemindai MRI dengan yang lain. Dalam prosedur cross-validation, kami membagi subjek secara acak di antara set pelatihan dan pengujian. Namun, apa yang akan menjadi konsekuensi dari pengacakan bukanlah subjek tetapi rumah sakit, dan karenanya pemindai MRI?Distribusi usia per rumah sakit. Rata-rata histogram intensitas voxel per rumah sakit: kiri, dinormalisasi hanya pada puncak materi putih (v1); kanan, dinormalisasi pada puncak materi putih dan materi abu-abu (v2). Mean Absolute Error (MAE) dan deviasi standar selama bertahun-tahun untuk berbagai algoritme level of evidence ” dalam kedokteran memungkinkan hierarki tingkat kepercayaan terhadap hasil yang dipublikasikan dalam makalah penilaian sejawat. Saat ini, tidak ada yang setara dalam machine learning.
Lebih jauh lagi dengan segmentasi jaringan
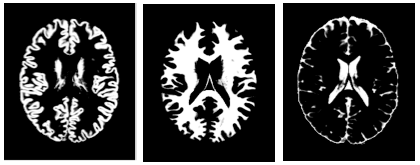
Dengan mereduksi seluruh MRI menjadi histogram, kami mengabaikan informasi spasial tentang struktur otak. Sebagai langkah berikutnya menuju algoritme yang lebih efektif dan bisa ditafsirkan, kami menggunakan paket software lain, FSL FAST , untuk membagi setiap MRI menjadi materi abu-abu, materi putih, dan cairan serebrospinal (CSF). Segmentasi ini didasarkan pada nilai voxel dan memberikan hasil meyakinkan yang bisa Anda lihat di notebook Colab kami .Tampilan masker segmentasi jaringan otak yang berbeda. Dari kiri ke kanan, masker materi abu-abu, materi putih, dan cairan serebrospinal (CSF) Mean Absolute Error (MAE) dan deviasi standar selama bertahun-tahun untuk berbagai algoritme.
Mari kita mulai dengan CNN!
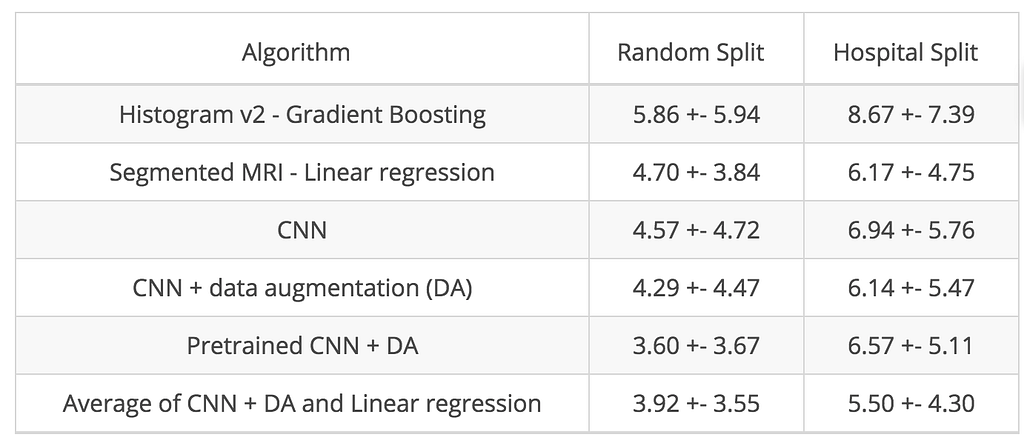
Ini adalah langkah terakhir dari petualangan kita. Sejauh ini, kami memanipulasi data untuk mengekstrak fitur yang kami anggap relevan dengan prediksi usia. Deep learning menghadirkan pendekatan lain dan menggunakan keluarga fungsi yang disebut Convolutional Neural Networks (CNN) yang bekerja langsung pada gambar mentah. Mereka mampu mengidentifikasi fitur paling relevan untuk tugas yang diberikan tanpa panduan manusia.notebook Colab .ResNet50 ) dan menyempurnakannya pada set data kami. Rangkaian hasil lengkap dari berbagai arsitektur CNN ditunjukkan di bawah ini:Mean Absolute Error (MAE) dan deviasi standar selama bertahun-tahun untuk berbagai algoritme
Metode ensemble untuk kinerja terbaik
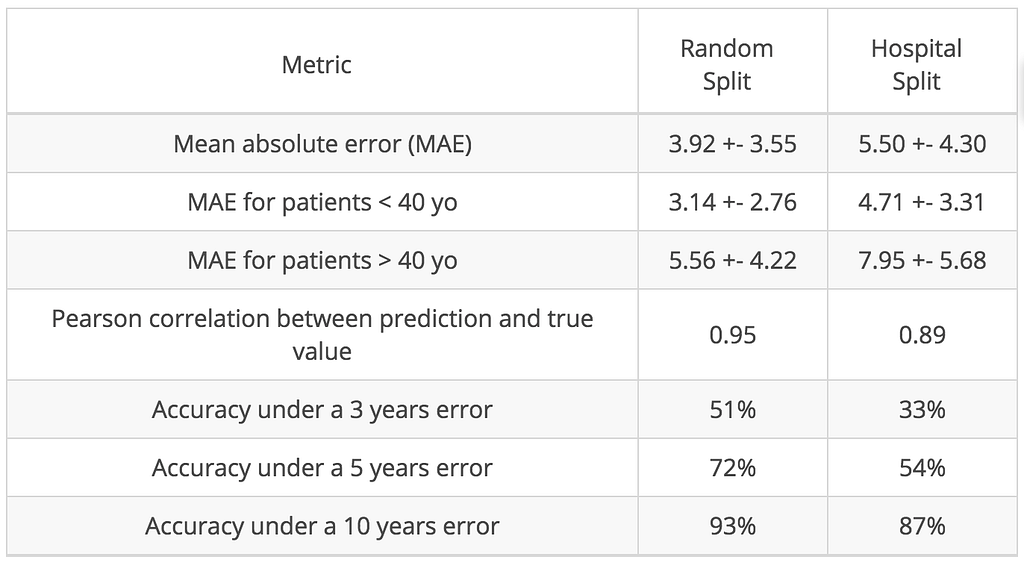
Sebagai trik terakhir, kami merata-rata prediksi dua algoritme terbaik kami: CNN dengan augmentasi data dan model linier pada MRI tersegmentasi. Sama dengan kolaborasi antar para pakar, metode ensemble membawa dorongan tambahan dalam kinerja, memperjelas bahwa kedua model ini berbeda tetapi saling melengkapi.Kinerja rata-rata pada 5-fold cross-validation untuk algoritme terakhir
Melihat ke dalam kotak hitam
Metrik kinerja mungkin meyakinkan, tetapi sering kali tidak cukup untuk membangkitkan kepercayaan. Algoritme seperti CNN, dengan jutaan parameter, sulit dipahami dan merupakan kotak hitam yang membuat frustrasi dokter yang mencoba memahami biologi di baliknya.Peta oklusi yang diperoleh untuk subjek dewasa di bawah 30 tahun (kiri), dan subjek di atas usia 60 tahun (kanan). Good et al., 2001 .postingan ini .
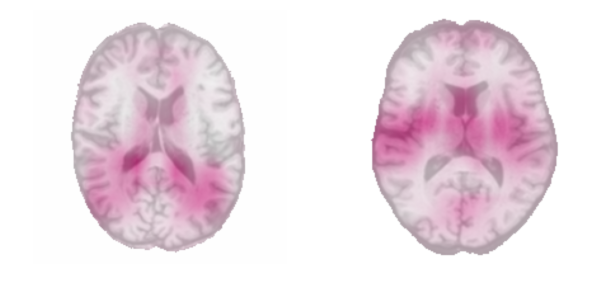
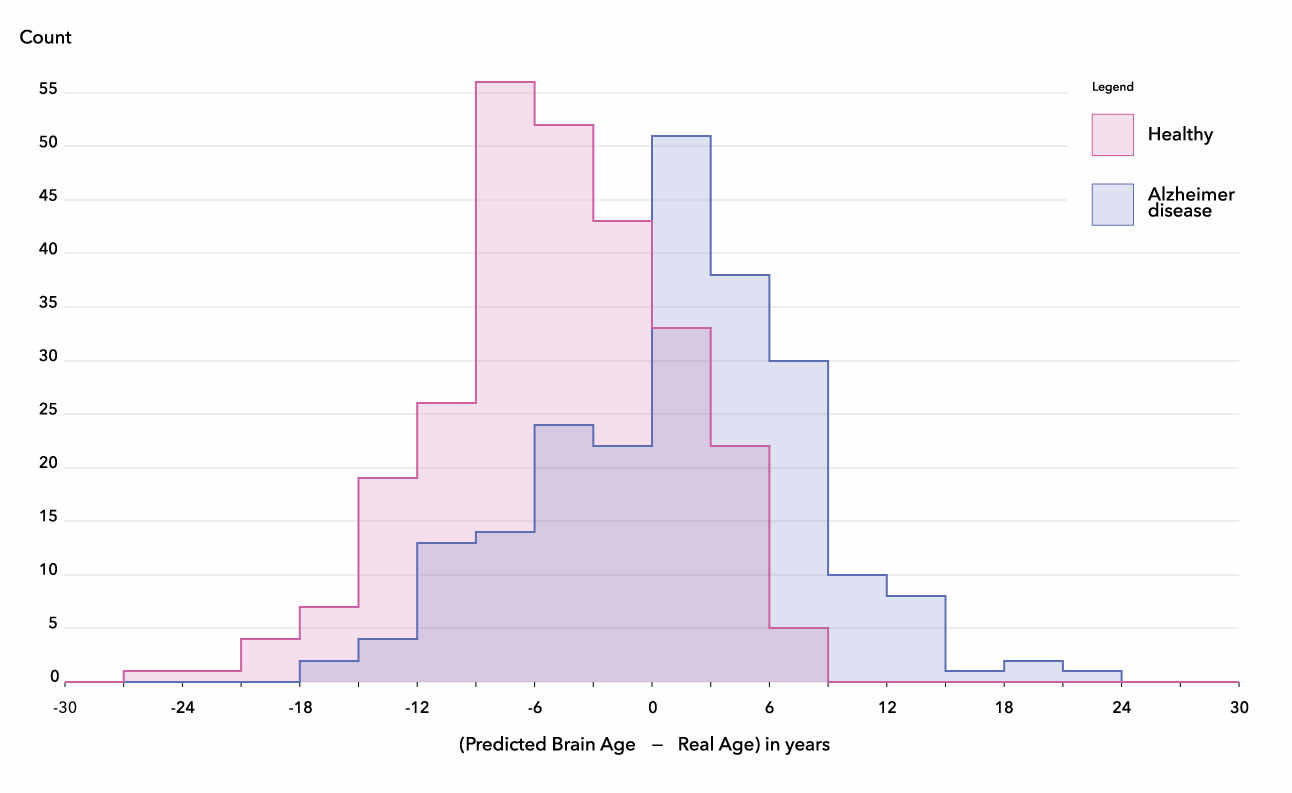
Menggunakan model kami untuk memprediksi penyakit Alzheimer
Aplikasi praktik latihan ini adalah memperkirakan usia fisiologis otak untuk mengembangkan pemahaman yang lebih baik tentang penyakit neurodegeneratif seperti penyakit Alzheimer. Sebagai eksperimen terakhir, kami menerapkan model kami pada 489 subjek dari database ADNI , dibagi menjadi dua kategori: kontrol normal (269 subjek) dan penyakit Alzheimer (220 subjek).Gaser et al., 2013 ), dan menguatkan hipotesis bahwa usia otak bisa menjadi biomarker baru untuk penyakit neurodegeneratif (Rafel et al., 2017 , Koutsouleris et al., 2014 , Coleet al., 2015 ).Distribusi perbedaan antara usia subjek yang diprediksi dan yang dilaporkan rata-rata berbeda 6 tahun antara kontrol normal dan penyakit Alzheimer pada 489 pasien dari database ADNI.
Kesimpulan
Prediksi dengan machine learning bisa dimulai dari penerapan model linier sederhana dalam hitungan detik hingga pembangunan CNN kompleks yang terus dilatih selama berhari-hari. Dalam kedua model tersebut, interpretabilitas sangatlah penting, terutama dalam kedokteran di mana ia bisa mengarah pada penemuan biomarker atau mekanisme biologis baru.
Ucapan Terima Kasih
Beberapa anggota tim Owkin berkontribusi dalam pekerjaan ini, termasuk Simon Jégou*, Paul Herent*, Olivier Dehaene dan Thomas Clozel. Kami berterima kasih kepada Dr. Roger Stupp, Dr. Julien Savatovsky, dan Olivier Elemento, PhD, atas dukungan aktifnya, Sylvain Toldo dan Valentin Amé atas pekerjaannya dengan angka-angka, serta Sebastian Schwarz, Eric Tramel, Cedric Whitney, Charlotte Paut dan Malika Cantor, untuk pengeditan naskahnya. Versi yang lebih panjang dari postingan ini tersedia di sini
Simon Jégou, data scientist: simon.jegou@owkin.com
Paul Herent, radiologist: paul.herent@owkin.com





Bonus 7x WIN Sabung Ayam SV388 Winning303
ReplyDeletePenawaran Promosi :
1.Promosi berlaku untuk Seluruh Member Baru Winning303 yang menggunakan Mata Uang IDR ( Indonesian Rupiah )
2.Promosi berlaku untuk Permainan Sabung Ayam SV388 Pada Situs Winning303
3.Bonus Tidak Dapat Di Klaim Apabila Mengikuti Promo Bonus Deposit
4.Syarat dan ketetuan berlaku.
Buruan langsung gabung bersama kami bosku, agar bisa menang kesempatan ini :
WA : 0877 8542 5244
atau langsung di Livechat kita www(titik)winning303(titik)org
>>>DAFTAR<<<
Winning303
data sgp
ReplyDeleteprediksi togel
data hk
idn poker
prediksi togel
poker99
judi poker
agen togel online
bandar togel online
This comment has been removed by the author.
ReplyDeleteGreat post. Saya tidak tahu bahwa usia otak dapat dihitung dengan alat. Bukankah usia otak sama dengan usia manusianya?
ReplyDeletelink alternatif login mobile
login alternatif sbobet
peraturan baccarat
download s128
daftar s1288
s128 asia
indomaxbet
aplikasi indomaxbet
daftar maxbet terpercaya
prediksi togel
ReplyDeleteprediksi togel
prediksi togel
prediksi togel
prediksi togel
prediksi togel
prediksi togel
prediksi togel
prediksi togel
daftar rajaqq
daftar omiqq - daftar playerqq - daftar kokiqq - daftar mejaqq - daftar diskonqq -daftar qiuqiu99 - jaguarqq - sahabatpoker
ReplyDeletenagaqq - taipanqq - daftar rajaqq - daftar laguqq - daftar mainqq - daftar idrpoker - daftar boyaqq - daftar kompasqq - daftar elangqq - daftar jasaqq
ReplyDeleteRajajudi14 Agen Judi Online yang terdapat banyak macam game hanya dengan satu usergame saja:
ReplyDelete- Judi bola
- Live casino
- Slots
- Lotre
- Poker
- ddan masi banyak lagi
Menawarkan berbagai bonus menarik diantaranya:
- Bonus New Member Sportbook dan Casino 20%
- Bonus Next Deposit 5%
- Bonus Cash Back 5%
- Bonus Turnover Poker 0,5%
Support Bank:
- BCA
- BNI
- BRI
- MANDIRI
segera kunjungi kami di website kami Rajajudi14
Permainan Sabung ayam sudah terkenal dimanapun tentunya dengan Ayam melawan ayam, Kami agent judi tepercaya tentunya bagi kalian yang berminat untuk bermain sabung ayam bisa datang ke situs kami :)
ReplyDeletesilahkan di klik link yang kita berikan :)
adu ayam s128
sabung ayam s128
agen s128 Indonesia
download aplikasi adu ayam
download aplikasi adu ayam online
download s128 sabung ayam
download s128 adu ayam
downliad s128.apk
s128 apk
aplikasi s128
install s128 apk
agen sabung ayam sv388
agen live casino sv388
daftar live casino sv388
register sabung ayam sv388
register sv388
daftar sv388 tembak ikan
daftar sv388 sabung ayam
Maxbet adalah permainan yang dapat memainkan taruhan Esport, bagi kalian yang sangat suka bermain permainan esports tentunya kalian ingin mendapatkan jajanan tambahan bukan ? silahkan kunjungi situs kami dan dapatkan uang jajan tambahan untuk kalian.
ReplyDeleteAgen Maxbet
agen judi bola maxbet
daftar maxbet
daftar akun maxbet
cara daftar akun maxbet
aplikasi maxbet
maxbet mobile
agen maxbet terpercaya
daftar maxbet
maxbet daftar
daftar akun maxbet
daftar ibcbet
login maxbet
maxbet deposit pulsa
withdraw maxbet
Link maxbet
live chat maxbet
login maxbet
login akun maxbet
situs login maxbet
deposit maxbet
maxbet deposit pulsa
maxbet338 asia
agen judi maxbet338
agen maxbet338
Prediksi HK
ReplyDeletePrediksi SGP
Prediksi Sydney
Data Sydney
Data SGP
Data Sydney
Data HK
Data HK
Data SGP
Data PCSO
Data Sydney
This blog article really helps us analyze and find answers or problems on the obstacles we face, extraordinary and very helpful, thank you
ReplyDeletehttps://hasilsidney.blogspot.com
Keluaran Sidney
Make money with XVIDEOS - Become a porn model คลิปโป๊
ReplyDeleteYour provided content is helpful. I've already bookmarked your website for the future updates.
ReplyDeleteultra high purity gas delivery systems
gas cylinder pressure regulator
gas accessories
Untuk memperkirakan usia otak, buatlah program dengan langkah berikut: gunakan metode MRI (Magnetic Resonance Imaging) atau data kognitif, lalu implementasikan model prediktif berbasis Machine Learning (seperti Random Forest atau Neural Network).
ReplyDeletebest family court lawyers near me
contract disputes
The Ehsaas Program Eligibility Checking Process is designed to help citizens determine whether they qualify for financial assistance under various government welfare schemes.
ReplyDeleteVisit Dentist in Milpitas for cosmetic, children, emergency, Invisalign, implants, restorative, general, technology services today.
ReplyDeleteExcellent services for growing startups everywhere. Company registration Private Public LLP Trademark Copyright Patent
ReplyDeleteTrusted practising company secretary in coimbatore offering Online Registration Services, Corporate Compliance Management Services , plus IPR Services.
ReplyDeleteGreat article! The information shared here is clear, practical, and very helpful—especially for businesses planning to expand into international markets. The content explains the IEC registration process, eligibility, required documents, and key benefits in a simple and easy-to-understand manner. This is a valuable resource for importers and exporters. Looking forward to more informative posts like this!IEC Registration in Bangalore
ReplyDelete