Untuk mengoperasikan sistem machine learning yang disesuaikan, tim perlu memiliki akses ke banyak fitur data untuk melatih model, serta menayangkannya dalam produksi.
GO-JEK dan Google Cloud dengan bangga mengumumkan rilis
Feast, toko fitur open source yang memungkinkan tim mengelola, menyimpan, dan menemukan fitur untuk digunakan dalam project machine learning.
Dikembangkan bersama oleh GO-JEK dan Google Cloud, Feast bertujuan memecahkan serangkaian tantangan yang sering dihadapi tim
machine learning engineering dengan menjadi platform terbuka, dapat diperluas, dan terpadu untuk penyimpanan fitur. Feast memberi tim kemampuan untuk mendefinisikan dan memublikasikan fitur ke toko terpadu ini, yang pada gilirannya akan memfasilitasi penemuan dan penggunaan kembali fitur di seluruh project machine learning.
“Feast adalah komponen penting dalam membangun sistem machine learning end-to-end di GO-JEK,” kata Peter Richens, Senior Data Scientist di GO-JEK, “kami sangat senang bisa merilisnya ke komunitas open source. Kami erat bekerja sama dengan Google Cloud dalam desain dan pengembangan produk, dan ini telah menghasilkan sistem yang kuat untuk pengelolaan fitur machine learning, mulai dari ide hingga produksi.”
Untuk penerapan produksi, tim machine learning membutuhkan beragam sistem yang bekerja sama.
Kubeflow adalah project yang didedikasikan untuk membuat sistem ini sederhana, portabel serta skalabel dan bertujuan untuk menerapkan sistem open-source terbaik bagi ML ke beragam infrastruktur. Kami saat ini dalam proses mengintegrasikan Feast dengan Kubeflow untuk menangani kebutuhan penyimpanan fitur yang melekat dalam siklus machine learning.
Motivasi
Data
fitur adalah sinyal tentang entitas domain, e.g: untuk GO-JEK, kita bisa memiliki entity pengemudi dan fitur dari jumlah perjalanan harian yang diselesaikan. Fitur menarik lainnya mungkin adalah jarak antara pengemudi dan tujuan, atau waktu. Kombinasi beberapa fitur digunakan sebagai input untuk model machine learning.
Dalam lingkungan dan tim besar, cara fitur dijaga dan ditayangkan bisa berbeda secara signifikan di seluruh project dan ini menghadirkan kompleksitas infrastruktur, serta dapat mengakibatkan duplikasi pekerjaan.
Tantangan yang biasa dihadapi:
- Fitur tidak digunakan kembali: Fitur yang merepresentasikan konsep bisnis yang sama dikembangkan lagi berkali-kali, ketika pekerjaan yang ada dari tim lain sebenarnya bisa digunakan kembali.
- Definisi fitur bervariasi: Tim mendefinisikan fitur secara berbeda dan mengakses dokumentasinya tidaklah mudah.
- Kesulitan dalam menayangkan fitur-fitur terbaru: Menggabungkan fitur yang berasal dari batch dan streaming, dan membuatnya tersedia untuk penayangan, membutuhkan keahlian yang tidak dimiliki semua tim. Menyerap dan menayangkan fitur yang berasal dari streaming data sering kali membutuhkan infrastruktur khusus. Dengan demikian, tim terhalang untuk memanfaatkan data real time.
- Inkonsistensi antara pelatihan dan penayangan: Pelatihan membutuhkan akses ke data historis, sedangkan model yang menayangkan prediksi membutuhkan nilai terbaru. Inkonsistensi muncul ketika data diisolasi ke dalam banyak sistem independen yang membutuhkan fitur terpisah.
Solusi kami
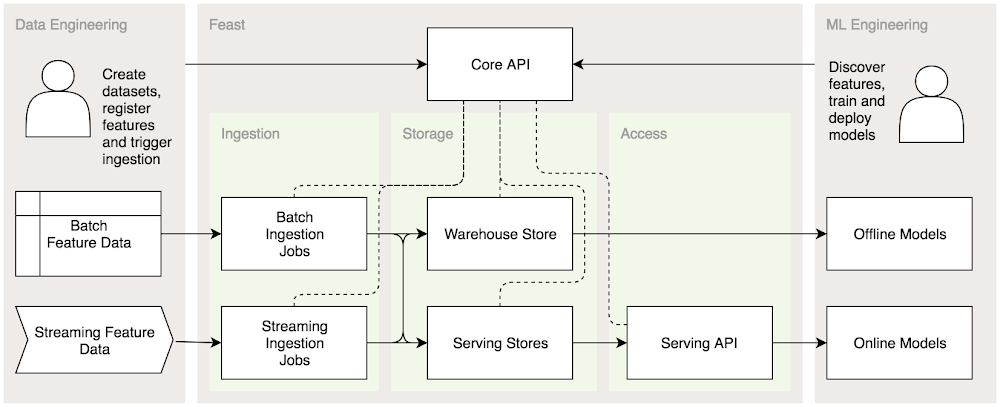
Feast memecahkan tantangan-tantangan ini dengan menyediakan platform terpusat untuk menstandarkan definisi, penyimpanan, dan akses fitur untuk pelatihan dan penayangan. Ia berfungsi untuk menjembatani data engineering dan machine learning.
Feast menangani penyerapan data fitur dari sumber streaming dan batch. Feast juga mengelola warehouse dan menayangkan database untuk data historis dan terbaru. Menggunakan Python SDK, pengguna bisa menghasilkan set data pelatihan dari warehouse fitur. Setelah model diterapkan, mereka bisa menggunakan library klien untuk mengakses data fitur dari Feast Serving API.